요즘 서울시 지하철 대시보드를 다시 만들고 있습니다. 아래는 녹화한 첫 번째 영상입니다. 공공데이터로부터 추출, 색인, 매핑 및 템플릿 설정 부분까지 진행했는데 이번 블로그에서 다루는 내용들이 있습니다.
색인된 정보들 중에 제일 자주 검색하는 것이 지하철 역명입니다. 물론 전부 keyword 로 해 놓고 정확한 역명만 선택되도록 해도 되지만, 그래도 검색엔진을 사용하는데 좀 더 편리하고 품질이 좋은 검색 기능을 만들어 봐야겠지요. 그렇게 하기 위해 오늘 이리 저리 했던 시행 착오들을 좀 공유 해 보려고 합니다.
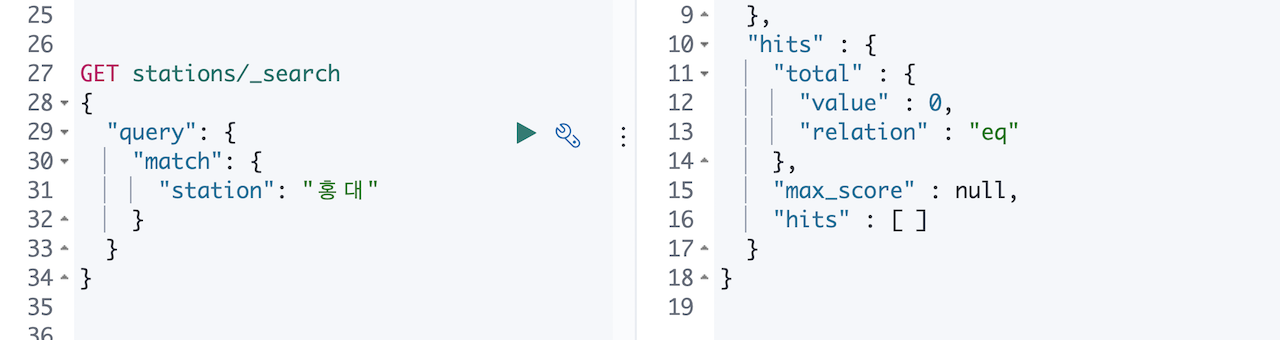
공공데이터에서 받은 데이터에서 추출한 지하철역 명 종류는 대략 900여개 입니다. 그 중에 검색 때문에 애를 먹이는 종류가 있었으니 바로 지하철역 명에 ***입구 라는 이름이 들어간 역 들입니다.
우선 테스트를 위해 stations 인덱스에 다음 10개 역명 문서를 입력하겠습니다.PUT stations/_bulk
{"index": {"_id": "1"}}
{"station":"홍대입구"}
{"index": {"_id": "2"}}
{"station":"서울대입구"}
{"index": {"_id": "3"}}
{"station":"총신대입구(이수)"}
{"index": {"_id": "4"}}
{"station":"충정로(경기대입구)"}
{"index": {"_id": "5"}}
{"station":"성신여대입구(돈암)"}
{"index": {"_id": "6"}}
{"station":"숭실대입구(살피재)"}
{"index": {"_id": "7"}}
{"station":"청량리(서울시립대입구)"}
{"index": {"_id": "8"}}
{"station":"한성대입구"}
{"index": {"_id": "9"}}
{"station":"숙대입구"}
{"index": {"_id": "10"}}
{"station":"남한산성입구"}
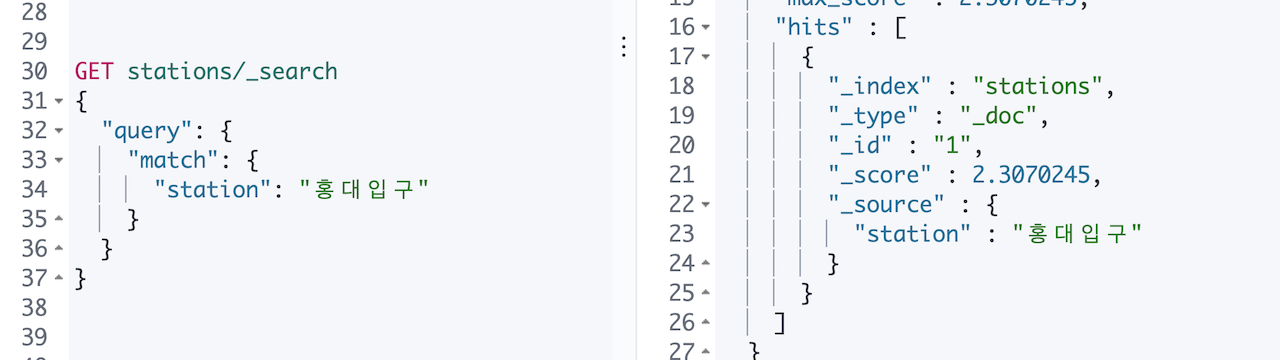
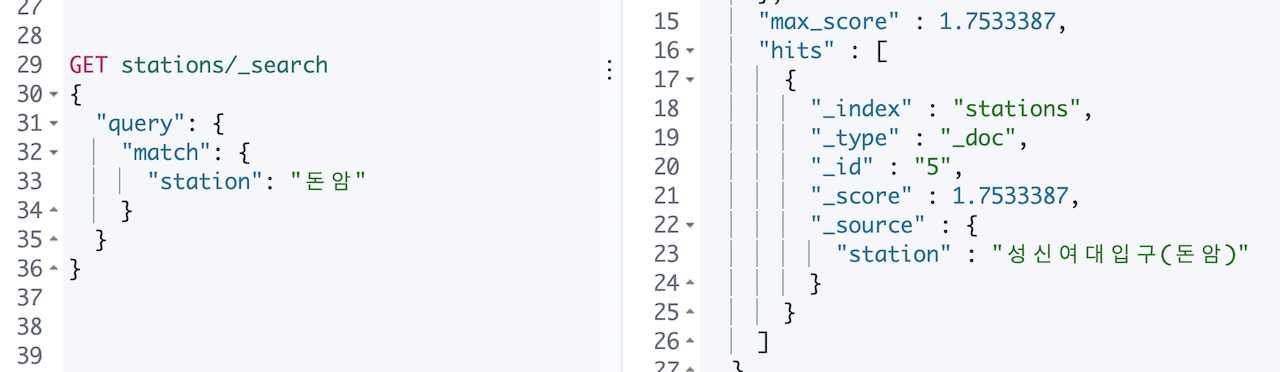
아무런 매핑 설정을 안 해줬으니 당연히 제대로 검색이 될 리 없습니다. 홍대, 서울대,입구 같은 검색어로는 검색이 안 되고 홍대입구, 숭실대입구 처럼 텀 전체를 정확히 넣어야 검색이 됩니다. 역명에 () 괄호가 같이 있는 역 들은 돈암, 이수 같은 검색어로도 검색은 되었습니다.
우선 아래와 같이 한글 형태소 분석기 nori_tokenizer 를 적용해서 멀티필드 station.nori 를 하나 추가하고 데이터를 다시 색인했습니다.PUT stations
{
"settings": {
"analysis": {
"analyzer": {
"nori": {
"tokenizer": "nori_tokenizer"
}
}
}
},
"mappings": {
"properties": {
"station": {
"type": "text",
"fields": {
"nori": {
"type": "text",
"analyzer": "nori"
}
}
}
}
}
}
이제 station.nori 필드로 검색을 하면 홍대 로도 검색이 됩니다.
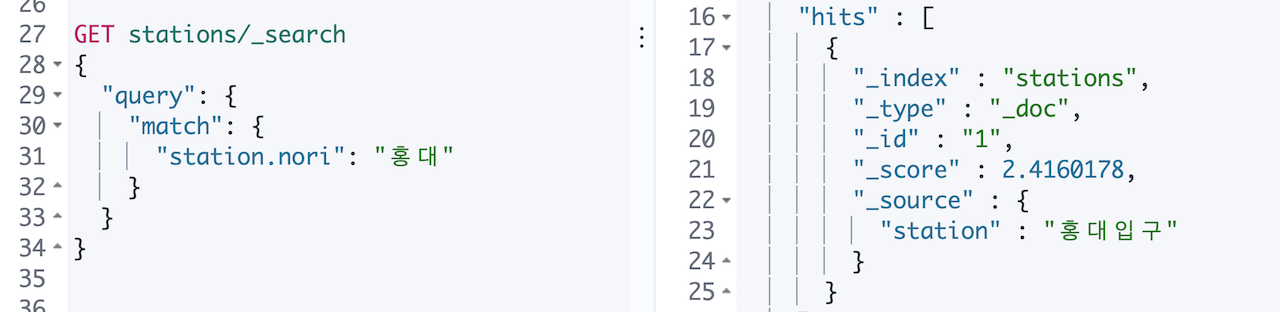
자, 이제 새로운 문제에 직면하게 되는데요, station.nori 필드에서 홍대입구 로 검색을 하게 되면 다음과 같이 입구를 포함한 모든 역명이 나오게 됩니다.
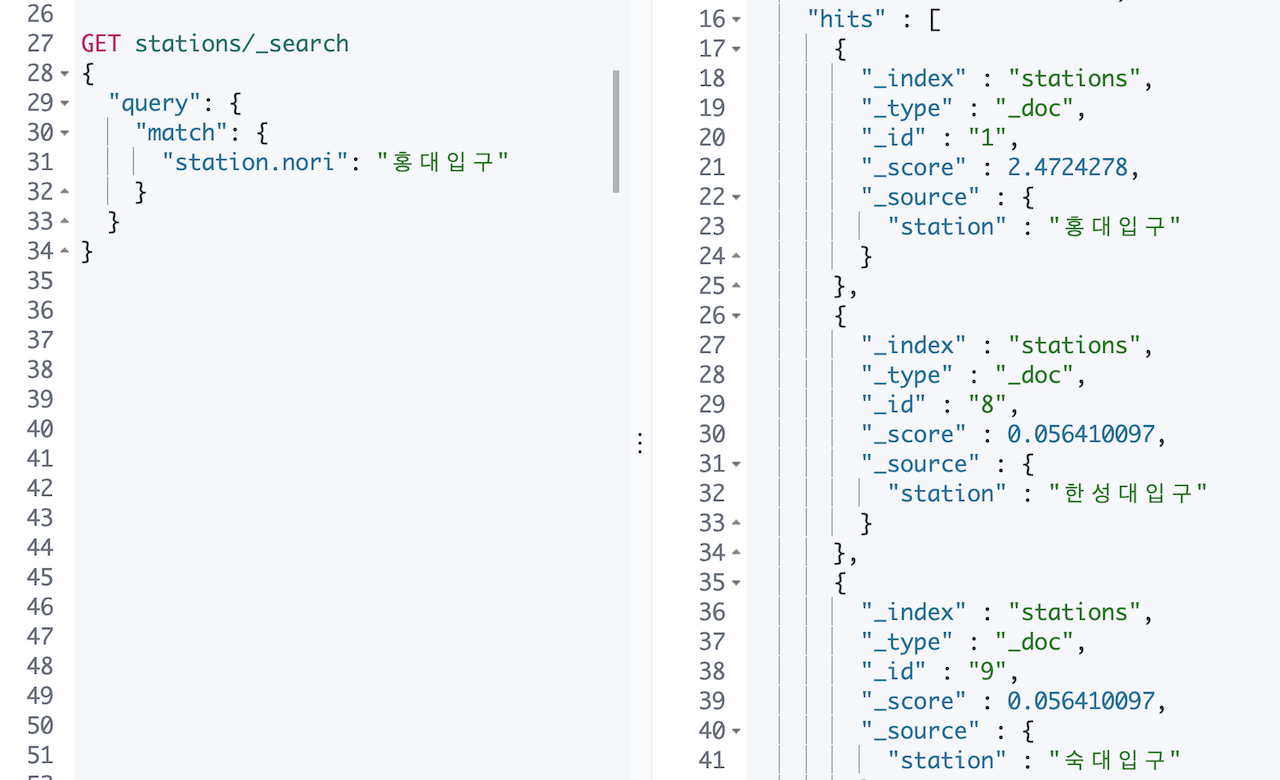
검색어로 넣은 홍대입구 가 홍대, 입구 로 분리되서 각각의 텀을 찾은 것을 쉽게 짐작할 수가 있습니다. 그럼 색인은 nori_tokenizer 로 하고 검색은 standard 로 하면 해결되지 않을까요?
매핑에 search_analyzer 를 standard 로 넣어 수정하고 데이터를 다시 색인 해 보겠습니다.
... |
다시 홍대입구를 검색어로 넣고 검색 해 보았는데
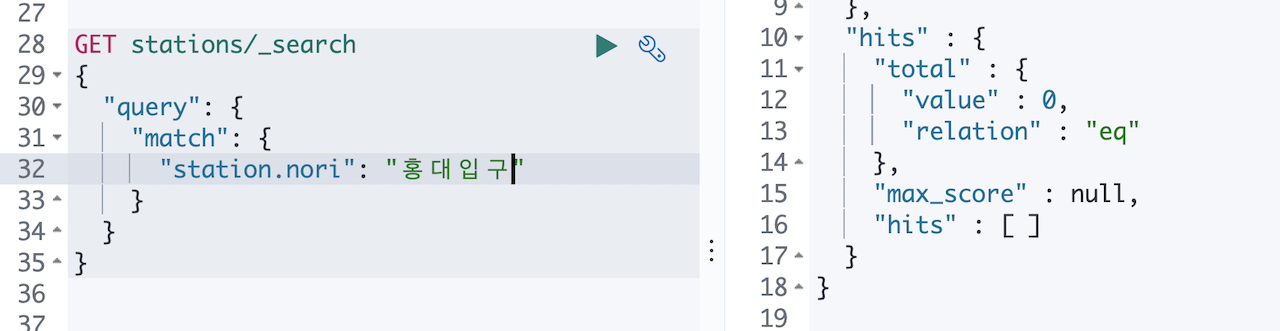
어라… 데이터가 나오지 않습니다. _termvectors 를 이용해서 색인된 텀 확인 들어갑니다.

역시 짐작대로 홍대 와 입구 만 있고 홍대입구 는 없습니다. elastic 홈페이지의 도큐먼트에서 nori 형태소 분석기 문서를 확인 해 봅니다.
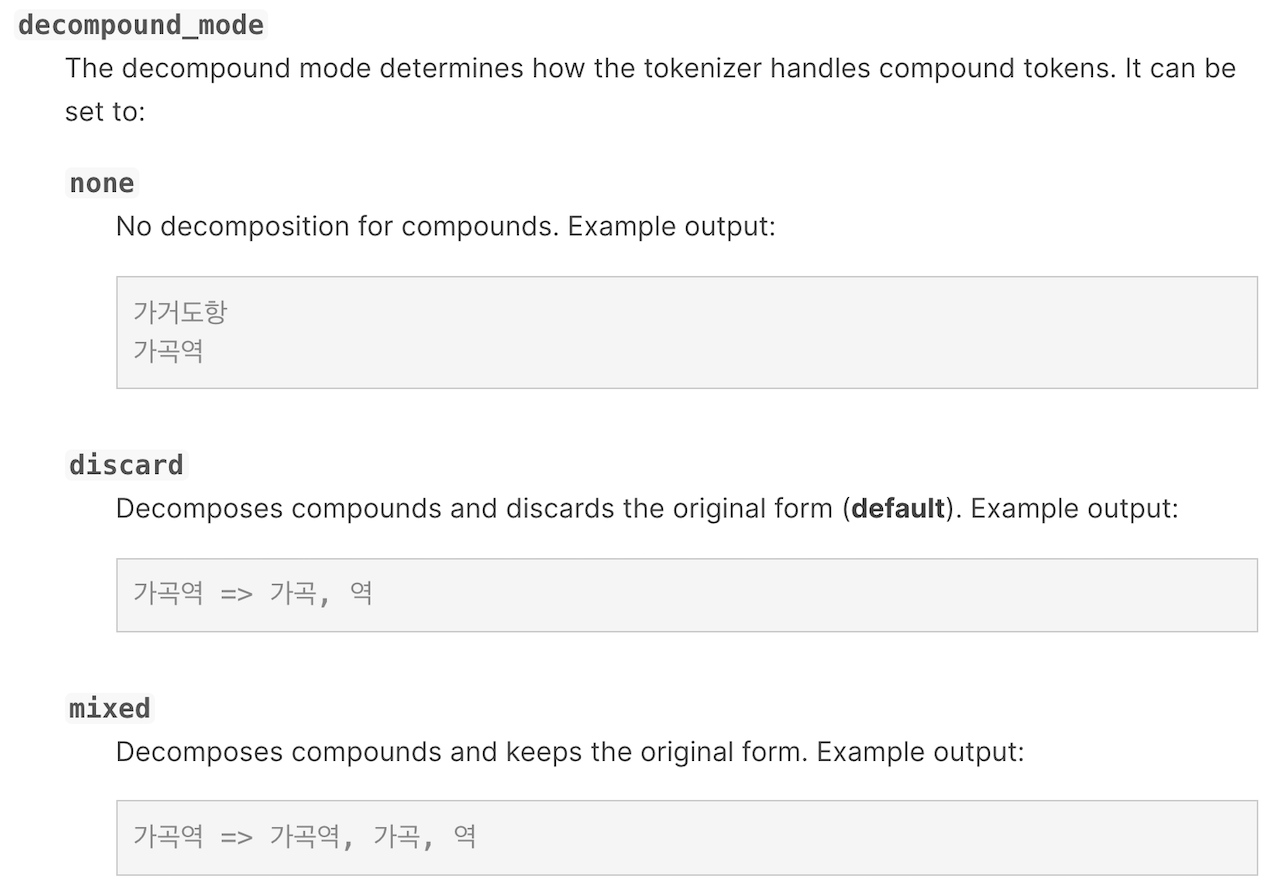
decompound_mode 설정의 디폴트 값이 discard 입니다. 그럼 이걸 mixed 로 바꾸면 홍대입구 텀이 저장되는지 해 봅니다. 인덱스 날리고, 매핑을 다시 만들고 데이터를 다시 색인 해 보겠습니다.
PUT stations |
여전히 안됩니다. _termvectors를 확인 해 보아도 아까랑 같습니다. 왜 그럴까요…?decompound_mode 옵션의 none, discard, mixed 값의 차이가 궁금해서 세개를 다 해 보기로 합니다. 매핑에 멀티필드로 nori_none, nori_discard, nori_mixed 를 만들어 보겠습니다.
PUT stations |
인덱스 삭제하고, 만들고, 데이터 다시 색인합니다. 다시 _termvectors 로 nori_none, nori_discard, nori_mixed 세개 필드를 확인 해봅니다.

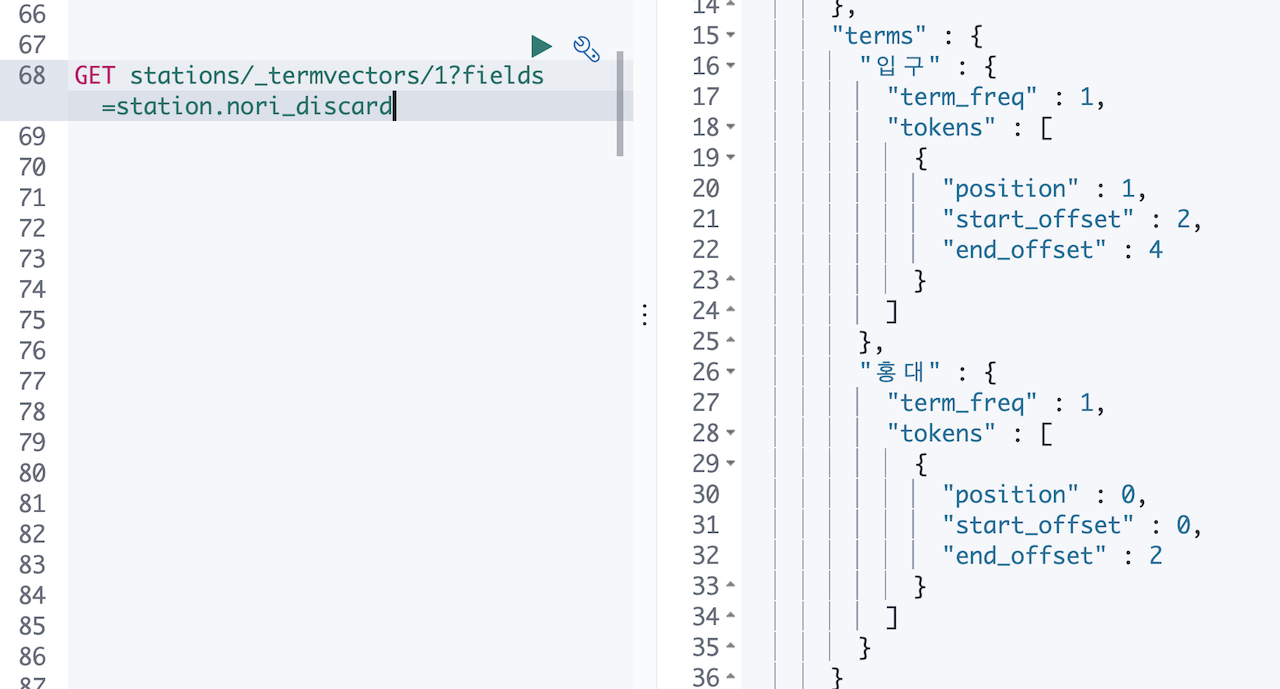
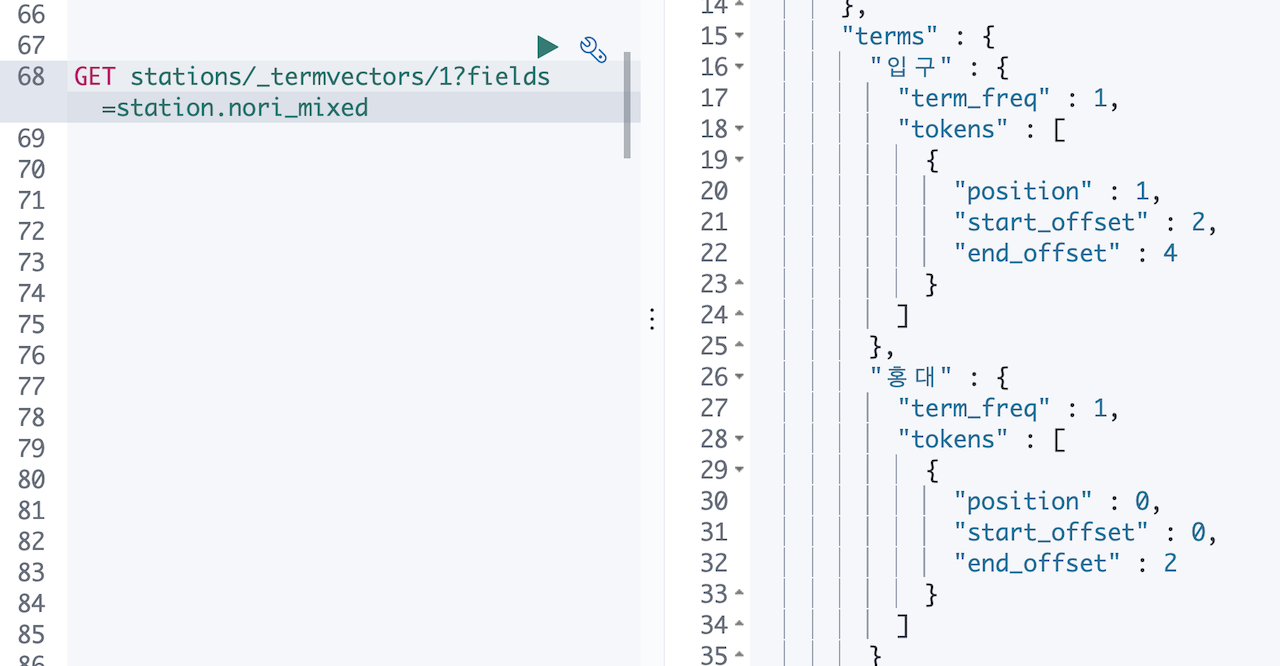
세개 모두 홍대, 입구 두개의 텀만 있고 차이가 없습니다.😳
이때 뭔가 머리를 스치는 느낌이 왔습니다. 이번에는 홍대입구 말고 서울대입구 가 저장된 도큐먼트의 값을 확인 해 보았습니다.
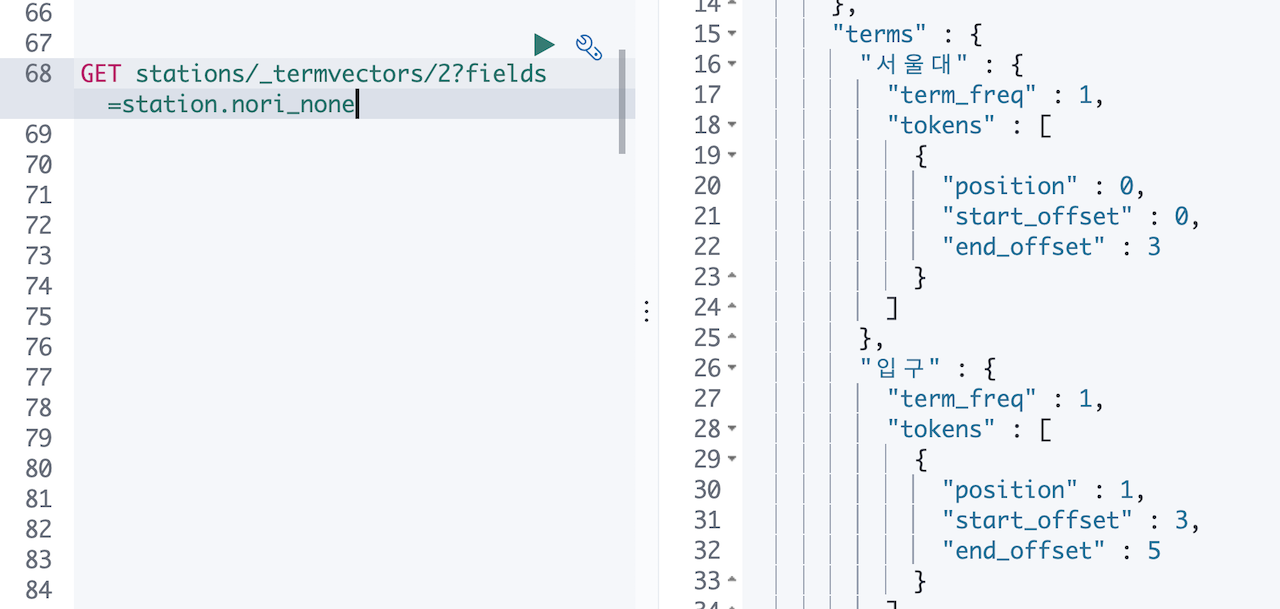
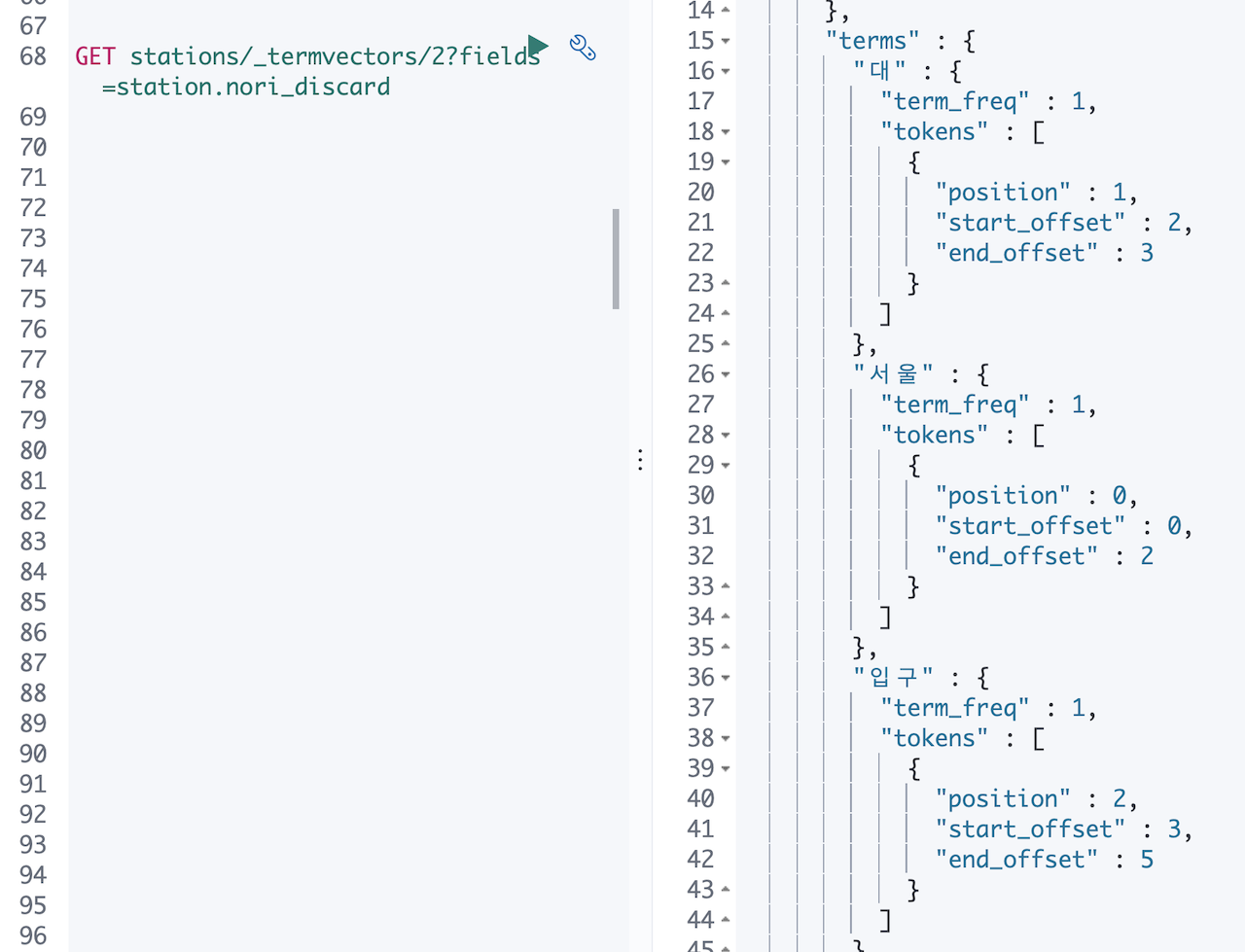
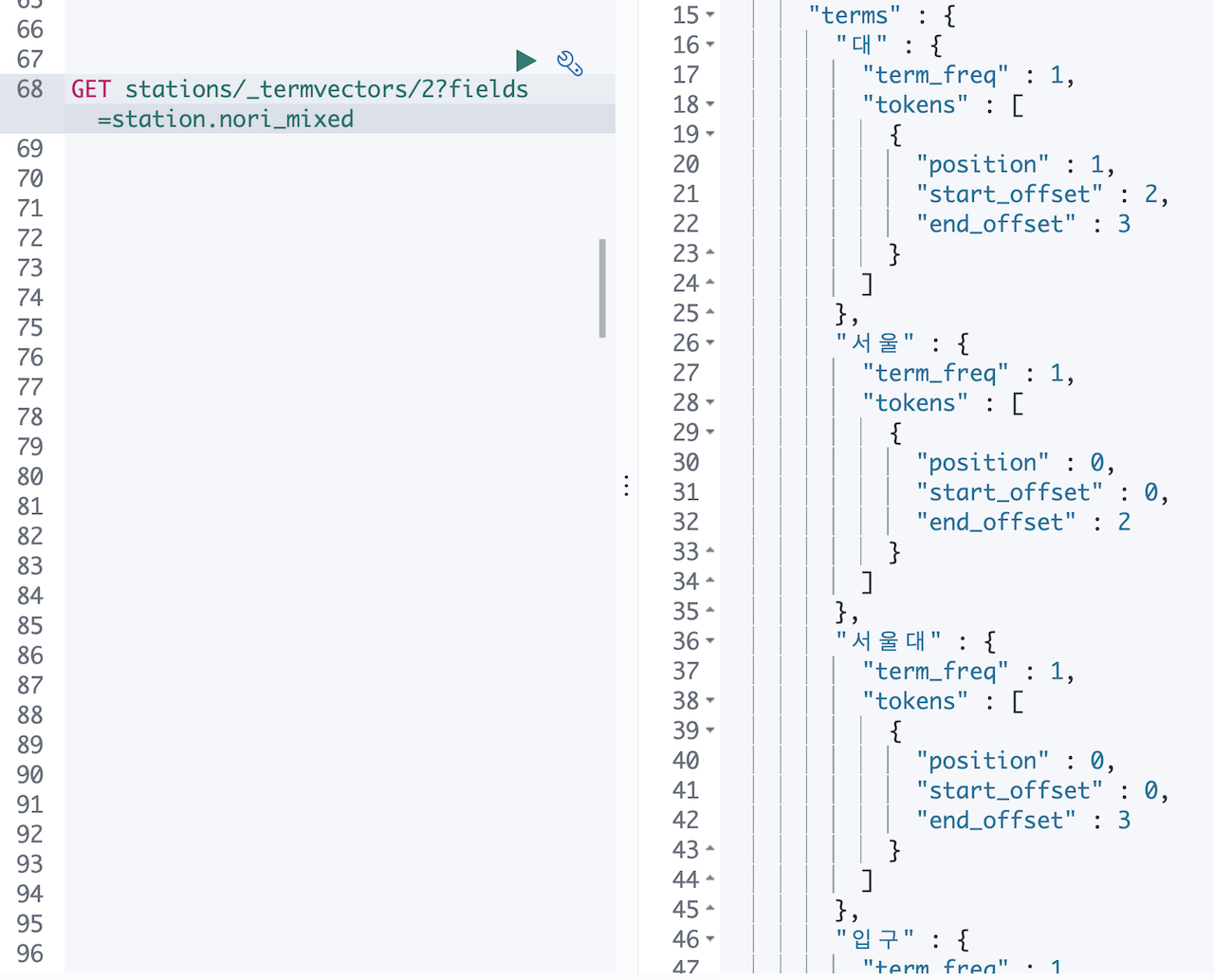
느낌이 맞았습니다. 홍대입구는 홍대와 입구 가 합쳐진 복합어로 치지 않고 두 텀을 모두 별개의 사전으로 간주합니다. 서울대 의 경우 서울 과 대 가 합쳐진 복합어로 쳐서 none, discard, mixed 세 옵션에 따라 서울대, 서울+대, 서울+대+서울대 이렇게 다른 모습으로 텀들이 저장됩니다.
그럼 지금 우리의 과제인 홍대+입구+홍대입구 를 모두 저장하는 과제는 어떻게 해야 할까요.
Elasticsearch 의 토큰필터 중에 나란히 있는 두개의 텀을 같이 저장하는 토큰필터가 있는데 바로 shingle 입니다. nGram 의 단어 버전이라고 보시면 됩니다. nori_discard 토크나이저에 shingle 토큰필터를 합쳐서 매핑을 다시 만들어봅니다. 다른 토크나이저는 지웠습니다.
인덱스 삭제하고, 매핑 수정하고, 데이터 입력하고… (벌써 몇번째인가요? 😩)
PUT stations |
다시 홍대입구의 텀 들을 확인 해 봅니다.
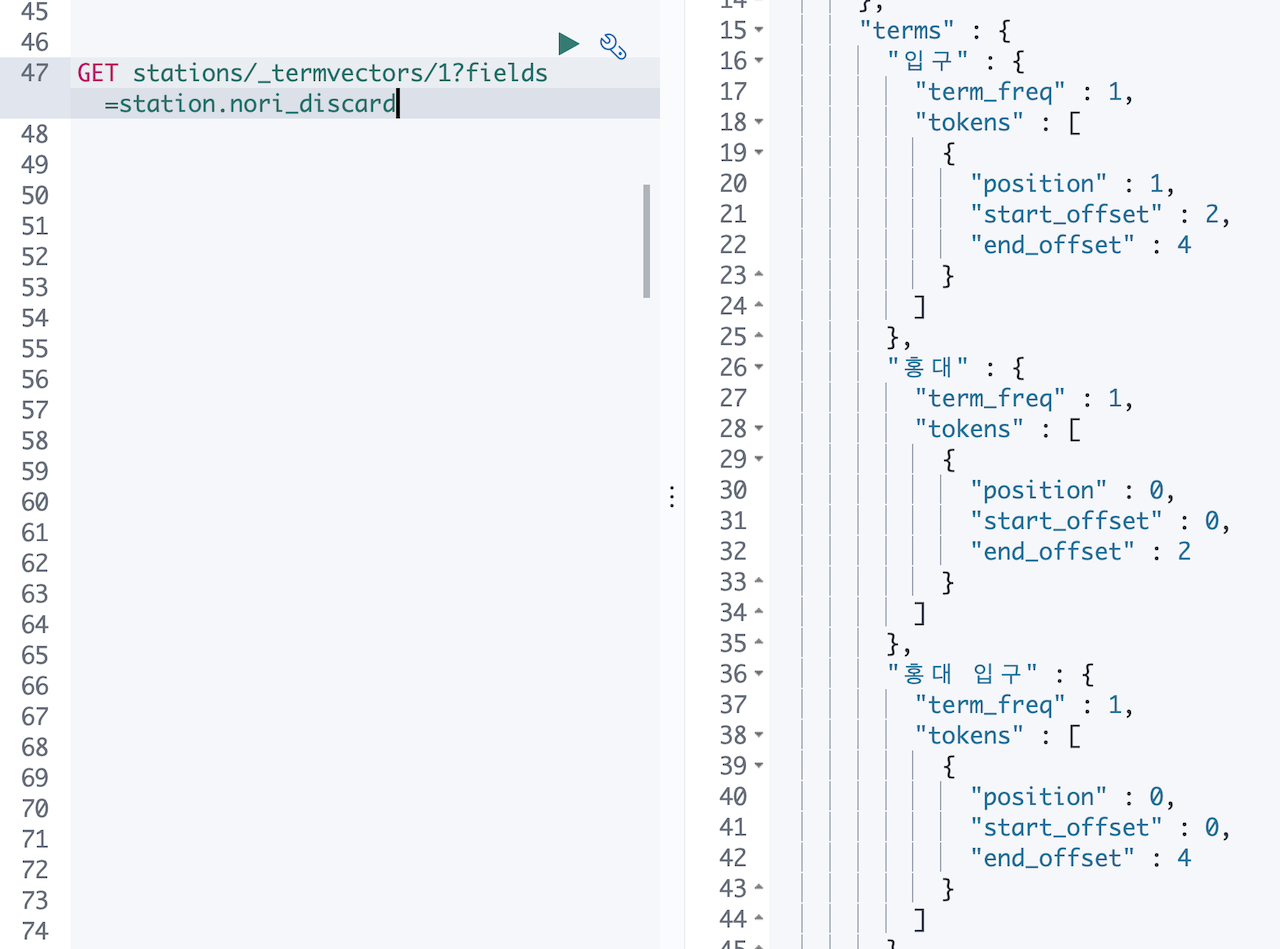
홍대, 입구, 홍대 입구 텀이 보입니다! 홍대 입구 텀이 가운데 공백이 들어가 있는데 이건 token_separator 옵션을 조정하면 해결하면 될 것 같습니다.
그리고 서울대입구 텀도 확인을 해 봅니다. 화면이 길어 캡쳐를 하지 않았는데, 나온 텀들은 다음과 같습니다.대, 대 입구, 서울, 서울 대, 입구
서울대입구 라는 텀을 만들려면 max_shingle_size 값을 3으로 해 주어야 할것 같습니다.
이제 다시 …
PUT stations |
이제 서울대입구 텀을 확인하면
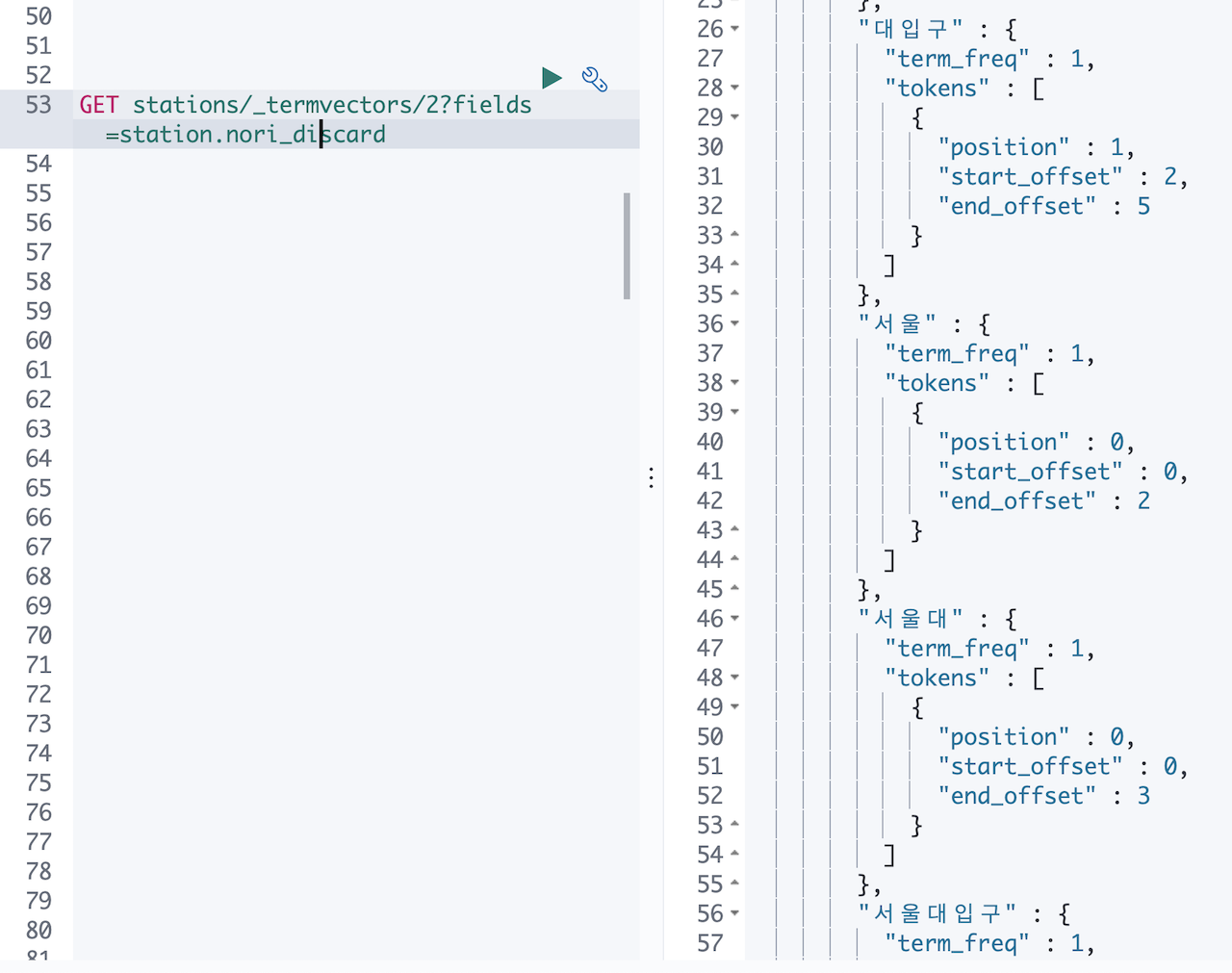
😭감격해서 눈물이 나네요. 이제 홍대입구 로 검색하면 입구는 제외되고 홍대입구 만 검색이 됩니다.

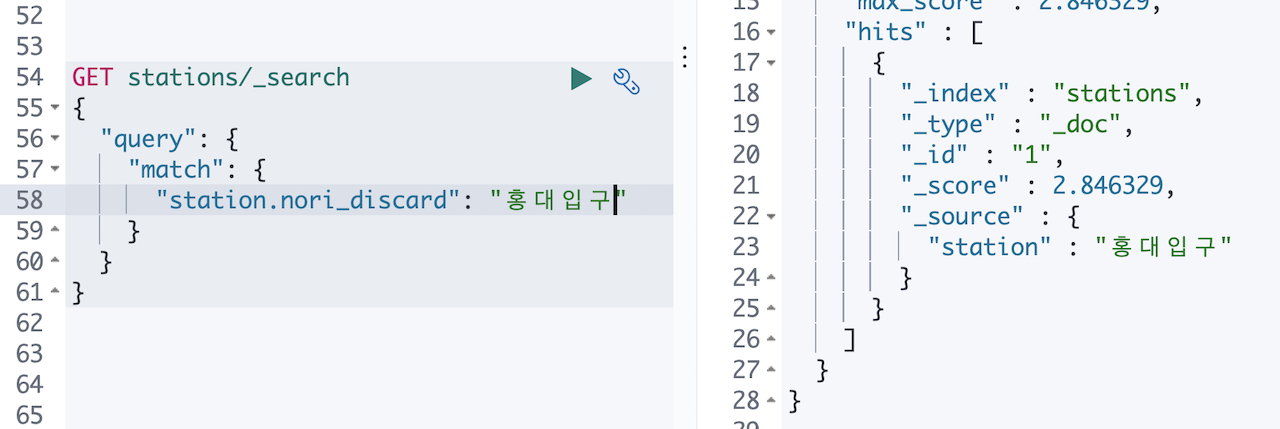
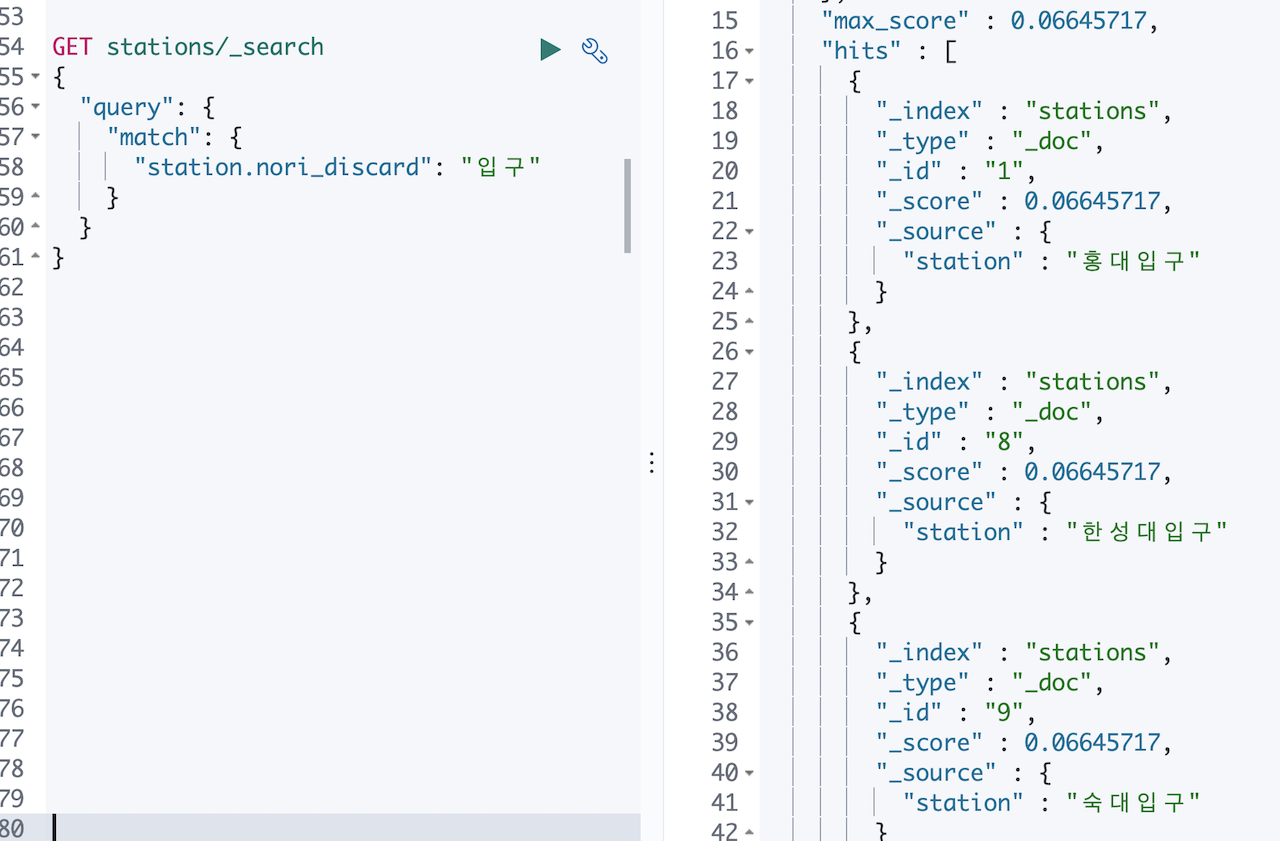
Elaticsearch, 시작은 쉽지만 잘 하려면 많은 고민과 노력이 필요합니다.
전문가가 필요하시면 저희 기술지원 구독을 문의하세요!! 😁
